Production Post Mortem
Context:
This is a post-mortem report for a production outage for a NodeJS application using a PostgreSQL database. The application was initially hosted on a single EC2 machine with the machine also hosting the PostgreSQL database.
As part of a larger plan, we migrated the database to a RDS instance.
What was reported?
- On Dec 23rd 11am, it was reported that almost all users are not able to use the dashboard. It seems like all the APIs (powered by NodeJS backend) are timing out.
- On Dec 25th 12pm, the same issue happened. All APIs(eg. Signup, Login, etc) are timing out.
What did we do?
- On Dec 23rd, we increased the EC2 machine to double its capacity from t2.medium to t2. large. The issue got resolved temporarily. After auditing the code, we realised we didn’t have necessary indexes setup in the database. (During this time, we still had the database running in the EC2 machine)
- On Dec 24th, as part of a larger plan, we migrated the data from the hosted Postgres to a RDS instance and pointed our backend to use RDS instance.
- On Dec 25th, one team member reverted the RDS configuration and directed the backend to use the database hosted in the EC2 machine. He thought that this was the root cause of the issue.
What actually happened?
-
We had a massive CPU spike on our EC2 instance (which was hosting both PostgreSQL, NodeJS). When looked at htop, it showed that PostgreSQL is using 99% of the CPU
-
After the migration to use the RDS database, we looked at the RDS logs. We clearly identified a big spike in CPU performance. At the same time, we didn’t see any drastic increase in the CPU usage for the EC2 machine hosting the NodeJS application.
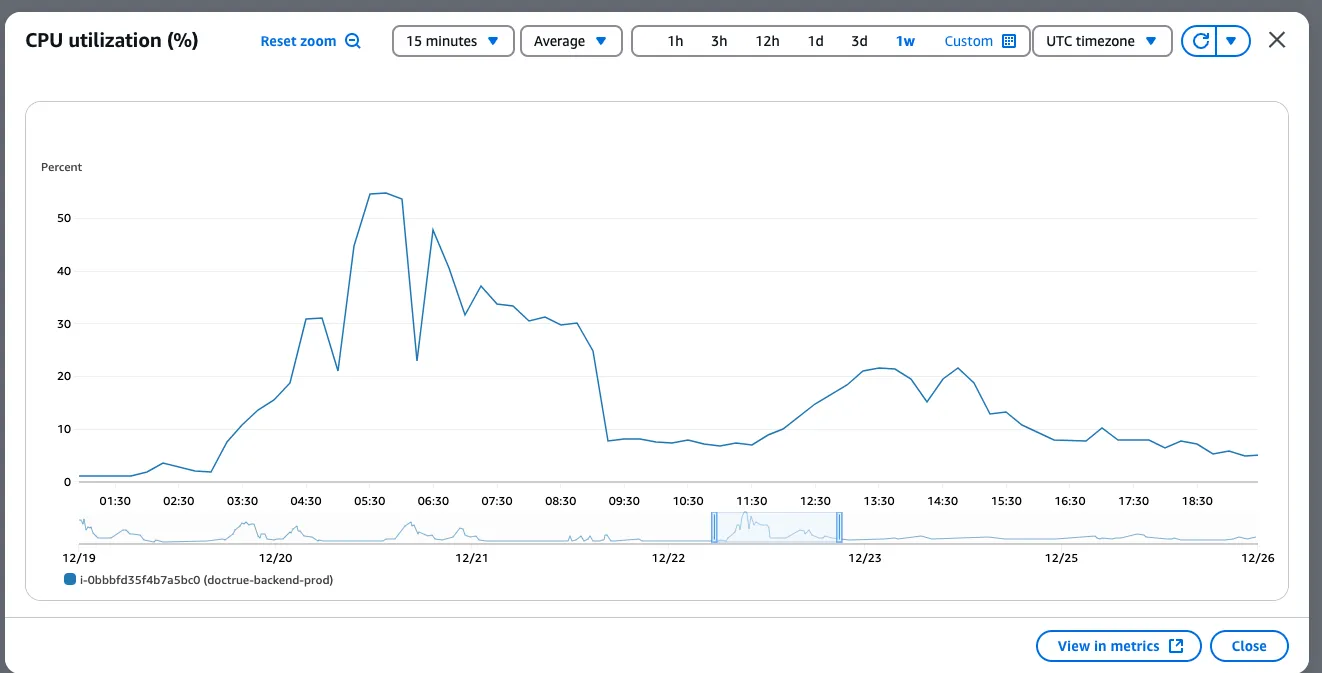
-
This is clearly a database problem. We added the indexes in the database and reverted back to using the RDS instance of the database (as we were anyways planning to). The same issue did not occur the following day. The CPU usage for the RDS instance hovered around 5% (unlike the previous spike).
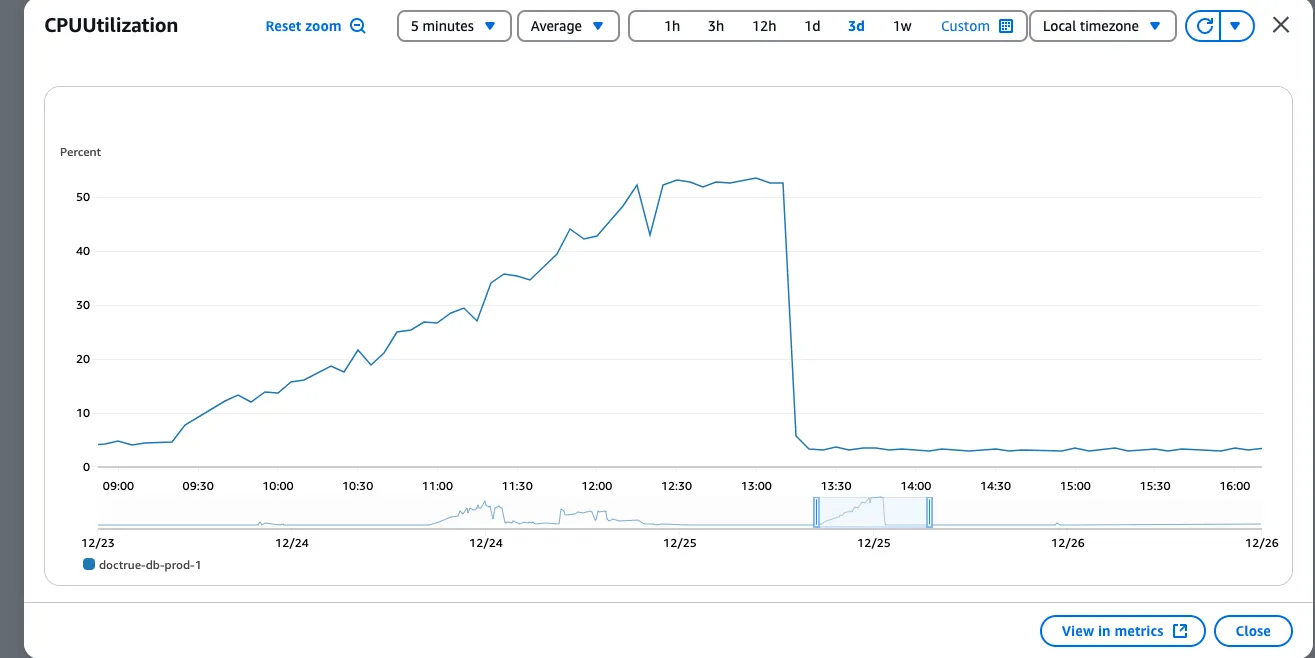
Notes:
- Having RDS (even briefly) helped us clearly identify the issue to be with the database. RDS metrics on AWS helped us identify the issue. We didn’t have the same visibility when the database was hosted in the EC2 machine.
- Indexes are crucial especially when we have queries that joins multiple tables. It’s a developer error to NOT factor the indexes to have when creating new APIs/features.
I write more about indexes and migrations in my previous blog.
I posted this blog to help others who might face similar issues. Let me know if you have any questions.